MyHeritage est un formidable outil, je l’ai déjà dit, mais une fois qu’on s’intéresse de près au sujet et à l’exploitation des données qui s’y trouvent, on se sent quelque peu gêné et limité par l’interface, certes sophistiquée et très intuitive mais parfois incomplète, de ce site. En fait, et c’est l’ancien développeur qui parle, on se dit assez rapidement que pour analyser les formidables données qiu s’y trouvent, il vaut mieux écrire ses propres bouts de programme.
Il existe deux manières de procéder pour cela. La première, c’est d’utiliser Family Graph, l’API MyHeritage, autrement dit l’interface de programmation. Elle existe depuis 2012, mais je n’ai pas encore eu le temps de m’y intéresser de plus près. La seconde méthode, et c’est l’objet de cet article, c’est ‘extraire les données et de traiter le fichier obtenu. Pour cela, il faut passer par un format standard de représentation de données de généalogie. Il en existe plusieurs, MyHeritage supporte le format GEDCOM.
Qu’est ce que GEDCOM ?
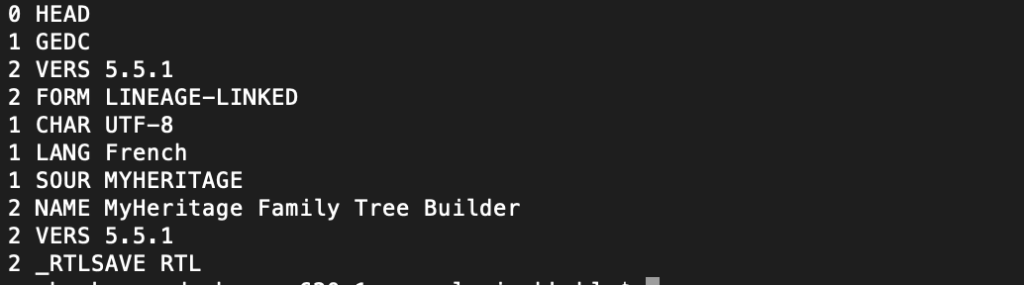
GEDCOM est un format inventé par les communautés de Mormons dans les années 90 pour représenter des fichiers de généalogie. C’est un format assez simple, non comprimé, les données s’affichant en clair, sous un format texte. La représentation des données se fait normalement en UTF-8, mais apparemment MyHeritage insère des caractères spéciaux (peut-être parce que les données que j’exporte contiennent des noms en français et en hébreu). ces caractères spéciaux bloquent la lecture du fichier en Python (ils provoquent une exception disant que le format n’est pas du UTF-8 standard). Pour éliminer ces caractères spéciaux, j’utilise une commande Unix simple:
iconv -c -f utf-8 -t asciiA l’intérieur d’un fichier GEDCOM, chaque ligne commence par un chiffre de 0 à 4, suivi d’un mot-clé de 3 à 4 caractères, suivi de la valeur associée au mot-clé. Le chiffre de 0 à 4 permet de structurer les données : les lignes commençant par 2 spécifient des données associées à la ligne précédente commençant par 1, qui elle-même spécifie des données rapportant à la ligne de niveau supérieur commençant par un 0.
Il y a plusieurs types de blocs de niveau 0:
- 0 HEAD : le header, qui indique l’origine du fichier (le logiciel utilisé pour le créer), le format, la date de création, etc.
- 0 @I123@ INDI : un bloc qui décrit un individu, identifié par son numéro @I123@. Une telle ligne est suivie de lignes qui décrivent l’individu : sa date de naissance, son lieu de naissance, sa famille ascendante ou sa famille descendante.
- 0 @123@ FAM : un bloc qui décrit une famille, caractérisée par ses membres (père, mère, enfants)
- 0 @S1@ SOUR : un bloc qui décrit l’origine des données
Pour plus de détails sur le format GEDCOM, il existe plusieurs sites, comme ici et là.
Vous prendrez bien un peu de Python ?
Pour exploiter un tel fichier, rien de tel qu’un peu de Python. On charge le fichier, on analyse ligne à ligne et on crée un tas de tables et de dictionnaires permettant de naviguer dans la structure. Il s’agit essentiellement de simples fonctions de parcours d’arbres. C’est ce que j’ai fait ces derniers jours. j’y ai ajouté un langage de requête spécifique, pour pouvoir lancer plusieurs types de requêtes, qui me permettent, par exemple de faire les analyses suivantes:
- liste alphabétique de tous les individus
- durée de vie moyenne d’une population
- nombre ou liste d’individus portant un nom ou un prénom donné
- nombre ou liste d’individus nés ou morts à une date donnée, une année donnée ou en un lieu donné
- ascendance ou descendance complète d’un individu
- lignée la plus longue dans un export GEDCOM
- chemin reliant deux individus quelconques (alors que MyHeritage ne permet que de calculer le chemin depuis un seul individu, le créateur de l’arbre)
Cette liste d’analyses est appelée à évoluer, par exemple pour rechercher d’éventuels doublons (dès qu’on dépasse quelques milliers d’individus, cela devient difficile à trouver), ou bien tenir compte des différences orthographiques ou des langues différentes pour les statistiques par nom ou prénom (je dois avouer que MyHeritage me bluffe à chaque fois qu’il reconnaît la retranscription d’un patronyme d’une langue à l’autre).
Pourquoi ne pas en faire un site ?
À terme, cet ensemble de scripts Python pourrait très bien devenir un mini-site internet écrit en Python. Mais pour cela, il faudrait que je fasse évoluer de manière significative le mode de représentation de données. En effet, en utilisant les librairies Python qui permettent de développer un site, il faudrait que je puisse conserver d’une page à l’autre la structure de données en mémoire. Ce serait assez peu performant, en fait, car le site ne tiendrait pas la charge en cas de requêtes simultanées.
L’alternative, bien entendu, c’est de stocker toutes ces données dans une base de données MySQL et de transcrire mes requêtes vers des requêtes SQL. Ce serait parfaitement possible, mais cela reviendrait, peu à peu, à construire une version simple et dégradée MyHeritage, ce qui serait un comble.
Dans un prochain article, je compte explorer l’API MyHeritage. À suivre…





